Comparing Reinforcement Learning to Optimal Control Methods on the Continuous Mountain Car Problem
What is the best way to get a car out of the bottom of a hill?
Introduction
This blog post was written by Jacob Mantooth,Dewan Chowdhury, Arjun Sethi-Olowin and published with minor edits.The team was advised by Dr.Lars Ruthotto.In addition to this post, the team has also given a midterm presentation, filmed a poster blitz video, created a poster, published code, and written a paper.
The word around town is that reinforcement learning is the top dog and has the answers to all our problems. We wanted to see if that really was the case, so this summer we took a trip to Emory University where we looked at the continuous mountain car problem to see if reinforcement learning really, was the best. The continuous mountain car problem is an example of an optimal control problem. In the image below you can see an example of what the continuous mountain car problem looks like.
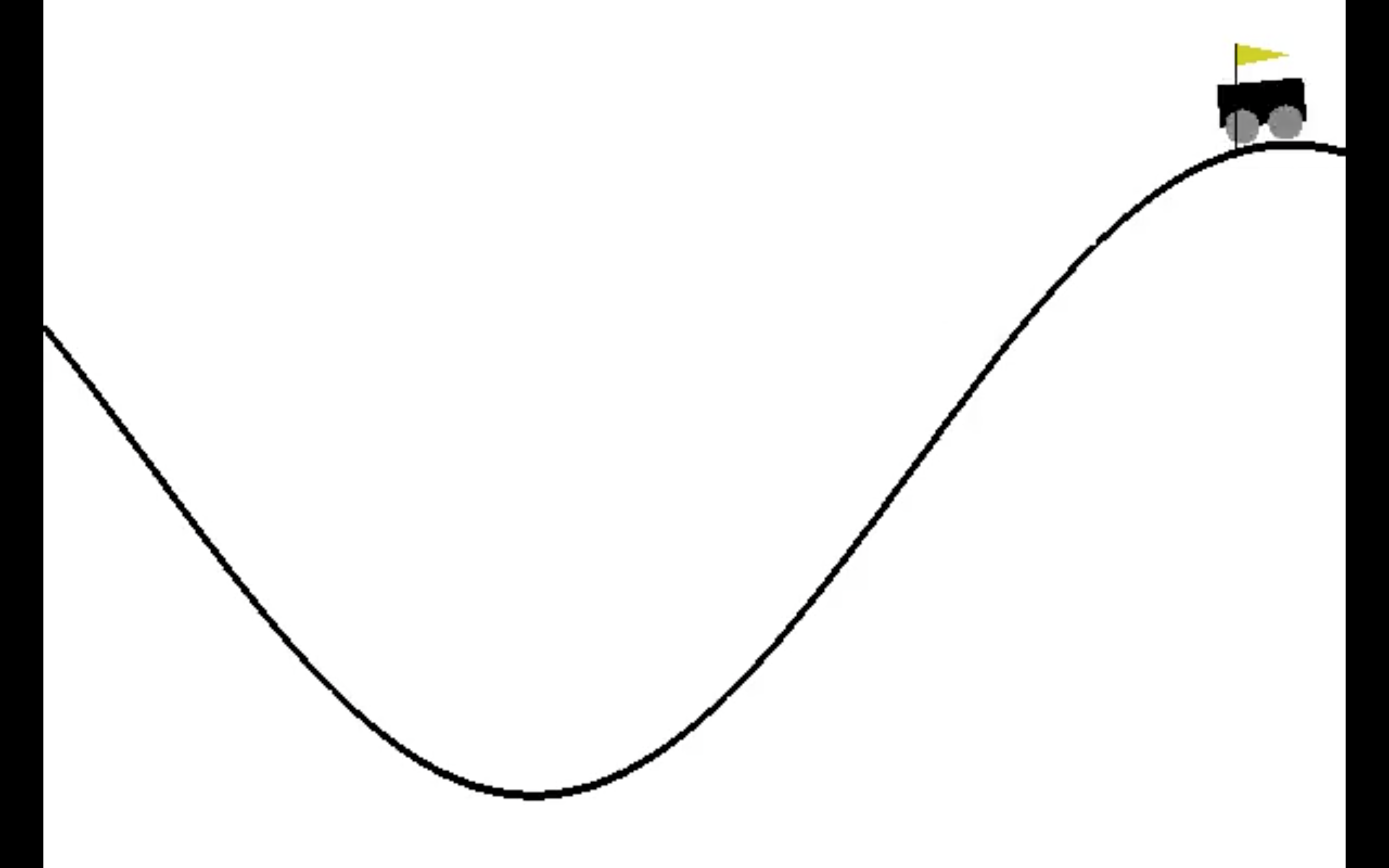
You may be asking yourself what is an optimal control problem? An optimal control problem is problem that consists of controlling a dynamical system to minimize (or maximize) a given objective function. In our case the continuous mountain can be modeled as a ODE where $u$ is some controllable function. In the continuous mountain car problem our control,$u$, is whether the car accelerates left or right. In an optimal control problem, we seek to optimize some objective function, in our case we will minimize the objective function. Our two objective functions are the running cost, which penalizes the car for acceleration. While our other objective function is the terminal cost which penalizes the car for not reaching the goal, the top of the hill, in time.
Why This Problem?
You may be wondering why choose the Continuous Mountain Car Problem? Here are a couple of reasons why we picked this example,
Established benchmark for RL models
2-D state-space allows for good plots and visualizations
Both RL and optimal control problem
Finite horizon (time)
Continuous state and motion
The whole reason we are doing this is because we want to compare three different ways of solving the continuous mountain car problem and see which one really is the best. Our three approaches are
Local solution using numerical ODE solvers and nonlinear optimization (baseline)
Reinforcement learning with actor-critic algorithm (data-based approach)
Optimal control using both model and data
Our Three Approaches
A Local Method
Our first method that we looked at during this REU was the local method. We tried to find the optimal control $u_h$ by formulating an optimization problem.
We first discretize the control, state and the Lagrangian.
Setting $z_h^{(0)}=z_t$ and $\ell_h^{(0)}=0$, allows us to use a forward Euler scheme for some control $u$.
We then approximate our objective function which yields the optimization problem
To solve our optimization problem, we used gradient descent. By taking an initial guess for $u_h$ and repeatedly updating $u_h$ using the gradient of the objective function and step size $\alpha$
$(u_h)_0 = \vec0$
$\vdots$
$(u_h)_6 = (u_h)_5 - \alpha( \nabla J((u_h)_5))$
$\vdots$
$(u_h)_* = (u_h)_19 - \alpha( \nabla J((u_h)_19))$
Below is a nice visual example of what all this math means. When the tail reaches the dotted line, it means our car has reached the top of the hill.
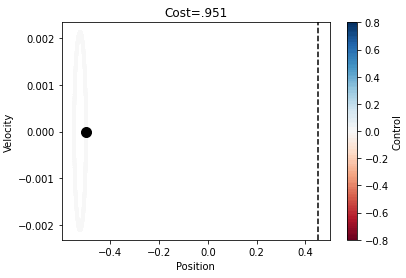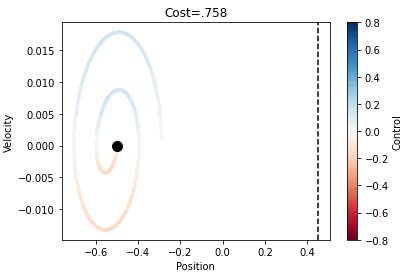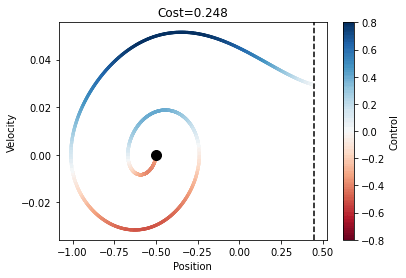
The graph shows us the position vs velocity of the car. In the graph the black dot represents t and the tail of the plot, when x-position is .45 is time T. In the graph we see the color change from red-blue, in our plot the blue color is when the car is accelerating, and control is positive but red otherwise.
Our next goal was how do we create a nice visualization of what the actual solution looks like.

We see in this video what our optimal local solution looks like. A couple of things that should be noted is, if we move the car to a new position then this local solution may no longer work. The same can be said if we slowed down/speed up a bit then this solution may not even let the car get to the top of the mountain. Another downside of the local is that it is a non-linear and non-convex problem which makes this method slow. This local solution will serve as a baseline so we can compare other methods to something to see which one is really the best.
Global Methods
Now that we have established a baseline, we will discuss our other two methods. Our other two methods that we will be looking at are global methods, the first being reinforcement learning method and the other being optimal control method. You may be asking yourself what is the difference? Reinforcement learning is more of a data driven approach while the optimal control method is a hybrid approach, using both a model and data.
Reinforcement Learning
Our first stop in exploring global methods is reinforcement learning. We will be using reinforcement learning with actor-critic algorithm. This approach is completely data-based approach. In reinforcement learning it has no knowledge of the model, it only considers the objective function. In reinforcement learning we would like to maximize a reward, so in our case we will maximize negative cost. Reinforcement learning is stochastic in two ways with initial position and action space which allows for exploration. In Reinforcement learning we are trying to estimate an optimal control policy. One of the big things that we have yet to discuss is, what is actor-critic algorithm ? The actor-critic (AC) architecture for RL is well-suited for a continuous action-space as in the continuous mountain car problem 1 . In the actor-critic algorithm the critic must learn about and critique whatever policy is currently being followed by the actor. We worked in the OpenAI gym mountain car environment, so we were able to find preexisting code for our project. We also were able to adapted the TD advantage actor-critic algorithm adapted from here. The thing is our preexisting code was not the same as our problem, so we had to modify it some. After some modification to the code, the following video is the results that we were able to get after many training cycles.

In this video we see that RL gave us a sub optimal solution compared to the local solution. You may also notice that in the reinforcement learning method our car takes an extra swing backwards to get to the top of the hill. In our reinforcement learning method it took 1000’s episodes just to get the car to our goal. We saw that reinforcement learning is very fragile, a couple of changes saw our success rate go from 70% to barely making it all. The picture below is position vs velocity of the car.
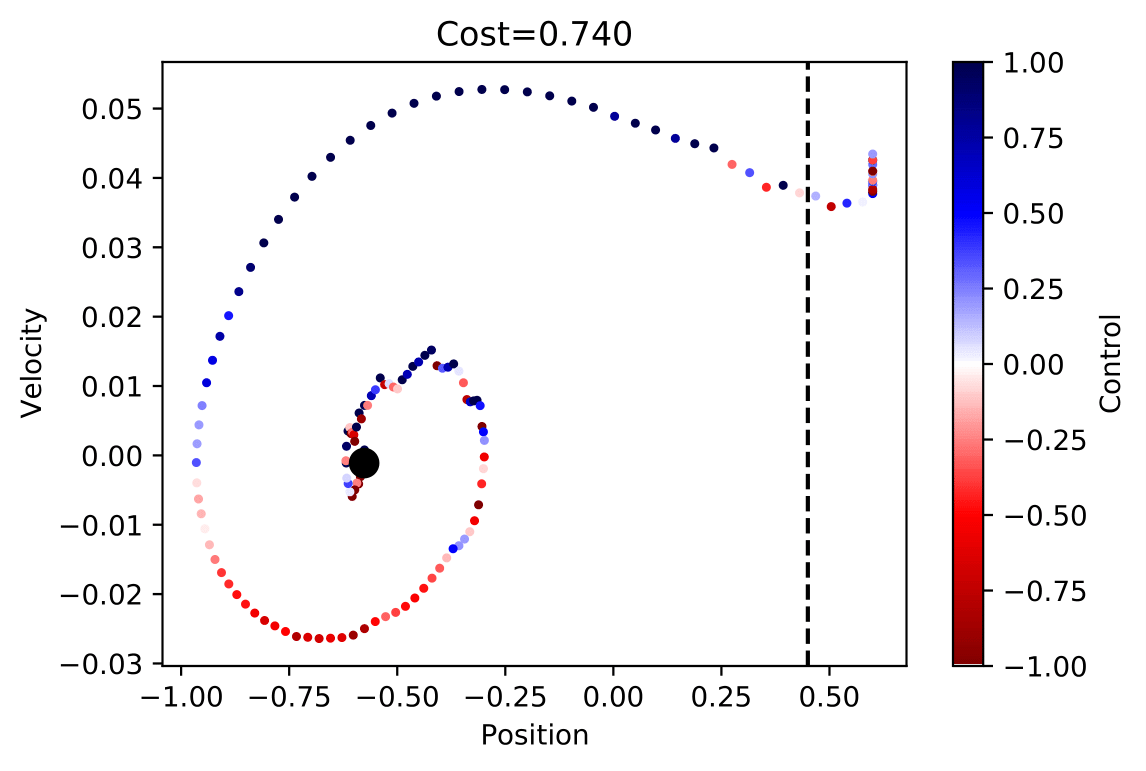
as you can see compared to the local solution, we see that the RL solution is very sub optimal solution.
Optimal control method
Our last two methods were vastly different with reinforcement learning using a data driven approach and the local method using a model-based approach. We will now be looking at the optimal control method which combines both model and data driven approaches. In this approach, we aim to adhere to the method discussed here. We will estimate the corresponding value function with neural network approximators utilizing feedback from the Hamilton-Jacobi-Bellman equation and Hamiltonian.
Using OC method we were able to produce the following
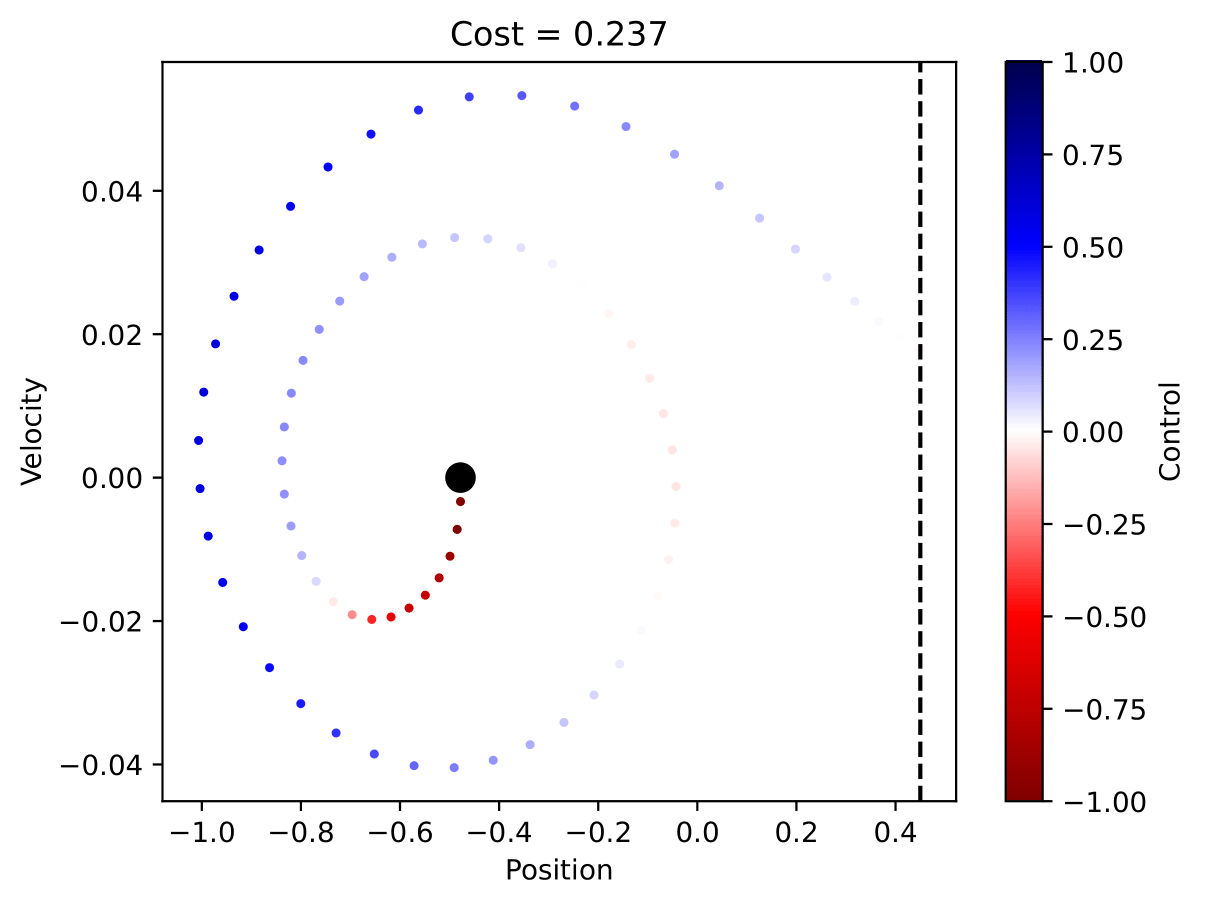
Once again, we created a position vs velocity of the car graph. As you can see this graph is a sub optimal solution compared to the local method. Compared to the RL method, we see how much better OC was for our problem. We see through testing of the RL method that there are some draw backs to forgetting the model and just being purely driven by data.
Our Experiences
Week 1
In week one we decided to make a game plan for the following weeks. We would work on the local method for just a week since it was basically finished. For the other two methods we would spend two weeks on each method. Lastly, we would save the last week to wrap up all three methods and anything else that is left over. During the first week we wanted to look at the local method and explore it some.
Week 2 & 3
We decided to spend two weeks to look at reinforcement learning, during these two week we were able to produce a PowerPoint in beamer for our mid-week presentation. In week two and three we looked at our first global method. Dr.Ruthotto handed us some pre written code to play around with. A thing that should be noted is that this prewritten code only worked maybe 50% of the time. Looking deeper into the code we realized that we would have to mess around with the code to get it to match our problem. After we made these couple of changes in our code, we saw how fragile reinforcement learning is, instead of working 50% of the time our code barely worked at all. During this week we were also able to produce a rendering of both of our local and RL methods, adding a nice touch to our presentation that we gave.
Week 4 & 5
During week 4 and 5 we looked at optimal control method. During week 4 we were able to produce a rough draft of the website while also taking a deeper look into optimal control method. Week five we created a rough and final draft of our poster. While working on our poster we were able to produce a graph for OC so we can compare it to our other methods.
Week 6
We wrapped up any unfinished work including our paper, OC method and this website. After struggling with code for method three we finally found that our OC method had better results than RL. During week six we also gave a poster talk to the Emory staff and students. Our group ended up winning best poster and we each won some amazon gift cards. We will continue working on method three to try and get it to work for 150 steps, we also look to fine tune our code for method three and two.
More About Our Team
Reference
U. M. Ascher and C. Greif. “Chapter 9 (Optimization).” A First Course on Numerical Methods. SIAM. SIAM,2011
U. M. Ascher and C. Greif. “Chapter 14 (Numerical time integrators).” A First Course on Numerical Methods. SIAM. SIAM,2011
Lars Ruthotto
Winship Distinguished Research Associate Professor
I am interested in developing efficient training algorithms for deep neural networks and their applications and data science and scientific computing (e.g., high-dimensional optimal control and PDEs).